



Can LLMs think?
Unmasking the Illusion of Thinking


Introduction
Recent generations of frontier language models have introduced Large Reasoning Models (LRMs). that generate detailed thinking processes before providing answers. Then we get a step-by-step breakdown that feels incredibly human-like thought chain. But does this effort really translate into genuine problem-solving power?
Apple's "Illusion of Thinking" study, investigates task performance of current Large Reasoning Models (LRMs), revealing that verbose reasoning traces do not equate to cognitive processes and that models falter significantly with increasing problem complexity. This underscores the necessity for architectural innovations beyond scaling.
Instead of standard benchmarks (which may have leaked into pre-training data), the authors built four classical puzzle environments—Tower of Hanoi, River Crossing, Blocks World, and Checker Jumping—In each puzzle, complexity is simply the number of fundamental elements (disks, checkers, pairs, or blocks). By varying only puzzle size or move limits, they isolated how true reasoning scales (or fails) as problems get harder.
To rigorously assess whether LRMs truly develop generalisable planning and problem-solving skills, we need
Controllable tasks whose difficulty we can dial up systematically
A way to inspect not only final answers but the entire reasoning trace.
Non-Thinking vs. Thinking Models
Basic Setup
Here is what they do to conduct this experiment. They want to compared prompting strategies across models, They pairs up the Models, as following
Claude 3.7 Sonnet: with thinking vs. no-thinking mode
DeepSeek: R1 (thinking) vs. V3 (no-thinking)
All runs are capped at the same maximum token budget (64 K tokens) to ensure fairness. Within that cap, “thinking” models produce a chain-of-thought (logged as thinking tokens), followed by a final answer. Non-thinking models emit only the answer.
By varying the allowed token budget from small (e.g. 5 K) up to the 64 K ceiling and measuring pass@1 (fraction of problems solved at the first time), the authors produce pass@k (fraction of problems solved at least once via k independent attempts) curves that fairly compare how much inference compute each model truly needs.
Models’ Performance Against the Complexity
Then, by varying the key parameter N from very small (e.g. 1–3 disks for the Tower of Hanoi) up to levels where the accuracy of the solution generated by both prompting strategies becomes negligible (this depends on the complexity of individual tests and the capability of AI models solving it), the teams identify three complexity “regimes.”
The authors identify, size of N (the puzzle-size parameter) in which the relative behaviour of non-thinking vs. thinking models:
Low complexity Regime - N small enough that even a brute-force or pattern-matching strategy suffices (e.g. 1–3 disks in Tower of Hanoi).
Medium-Complexity Regime - N large enough that models start to make mistakes, but still below the point where an optimal solution requires prohibitively many steps (e.g. 4–7 disks in Tower of Hanoi).
High-Complexity Regime - N so large that the search space explodes (e.g. ≥8 disks), making exact planning impossible within any realistic token budget.
We will discuss the reason after we go through one last test.
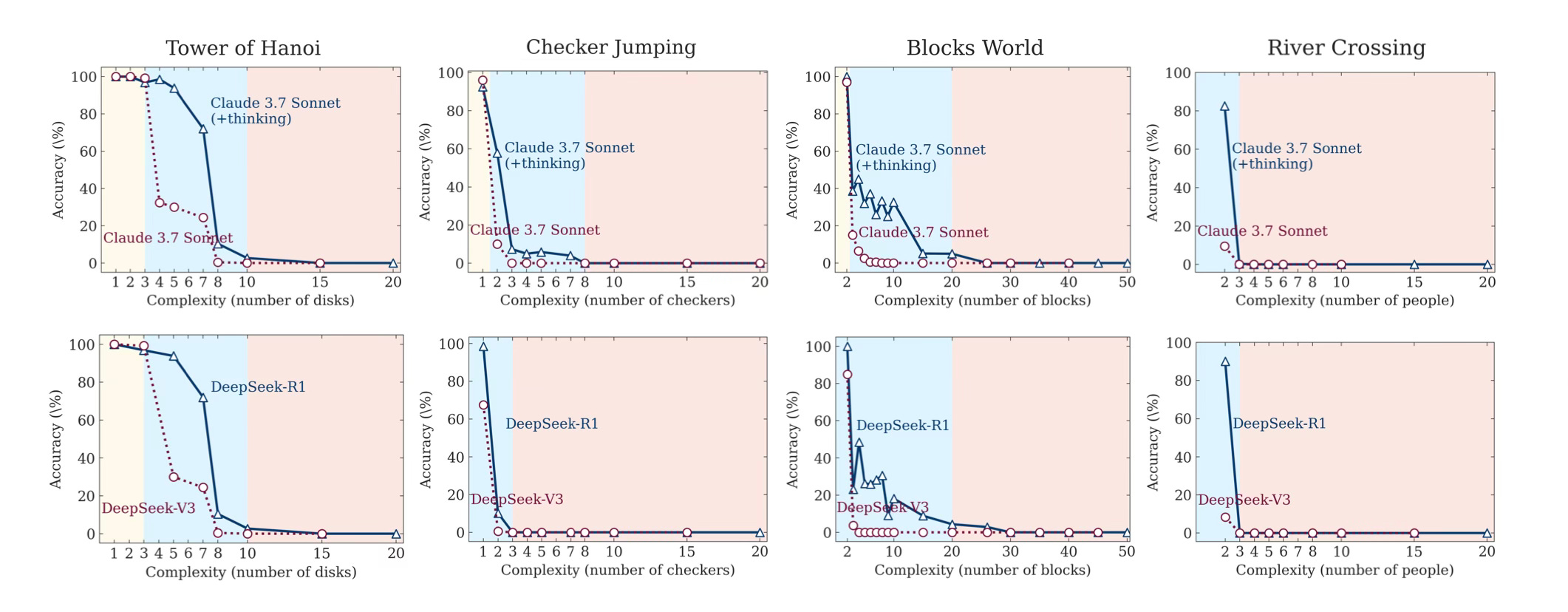
Image above : Accuracy of thinking models (Claude 3.7 Sonnet with thinking, DeepSeek-R1) versus their non-thinking counterparts (Claude 3.7 Sonnet, DeepSeek-V3) across all puzzle environments and varying levels of problem complexity.
Token Budgets Taken : Non-Thinking vs. Thinking Models in Different Complexity Regime
After that, the team ran an experiment on Pass@k performance of thinking vs. non-thinking models across equivalent compute budgets in puzzle environments of low, medium, and high complexity. Non-thinking models excel in simple problems; thinking models show advantages at medium complexity, while both approaches fail at high complexity regardless of compute allocation.
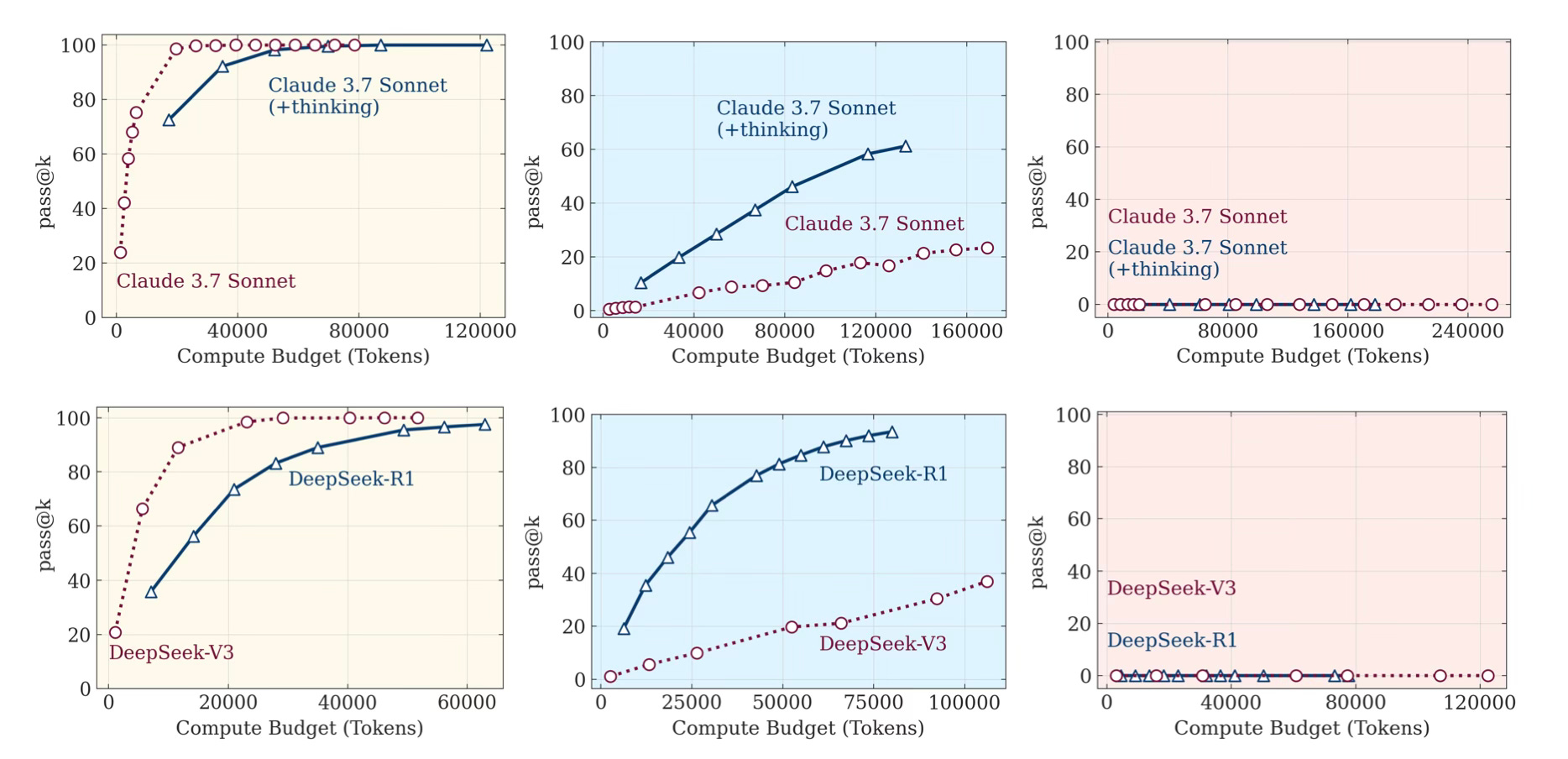
Image describes: Pass@k performance of thinking vs. non-thinking models across equivalent compute budgets in puzzle environments of low , medium , and high complexity. Non-thinking models excel in simple problems, thinking models show advantages at medium complexity, while both approaches fail at high complexity regardless of compute allocation.
And they summarise: At the Low-Complexity Regime, standard LLM models (Non-Thinking Models) often match—or even slightly outperform—reasoning models (Thinking Models), and do so using far fewer tokens. In this regime, the overhead of generating lengthy CoT cannot actually improve the result. At the Medium-Complexity Regime, the “thinking” models’ planning ability pays off: they maintain higher accuracy than their non-thinking 'siblings', though they require more computation. At the High-Complexity Regime, both thinking and non-thinking models fail—accuracy collapses to (near) zero. Interestingly, reasoning models even begin to shorten their thinking process as N grows further, despite still having unused token budget.
Key Takeaways
“Thinking” models only outperform standard LLMs in a medium-complexity regime.
All Models Collapse Beyond a Threshold: All reasoning models eventually hit a hard ceiling: accuracy falls to zero once N crosses a threshold limit.
Counter-Intuitive Compute Scaling: As problems grow harder, LRMs initially “think harder” (use more tokens), but just before collapse they start producing shorter reasoning traces—even though there is token budget remains.
Overthinking and Self-Correction Patterns: In easy puzzles, "thinking" models often hit the correct move early yet continue exploring wrong ones (“overthinking”), wasting compute. In hard puzzles, no correct moves appear at all.
Together, these findings challenge the idea that longer chains of thought alone will unlock human-level reasoning. Instead, they point toward deeper architectural and training innovations—perhaps hybrid symbolic-neural methods or new meta-learning schemes—needed to surmount the hard complexity ceilings we observe right now.
Justin Ju
| AI Engineer at Chelsea AI Venture | justin@chelseaai.co.uk |
If you are interested in implementing AI solutions in your company, please subscribe to this channel. We will be sharing methodologies for implementing AI into business ideas and providing tech solutions to different problems.
At Chelsea AI Venture, we are offering services for scaling up AI in SMEs and we occasionally organise tech training events. Do not hesitate to contact me via email or by visiting our website for any questions or business cooperation opportunities.
If you’re tired of slow, bloated forms—give KirokuForms a try. It is a smart, fast form building solution powered by Chelsea AI Venture. Spin up a free project at KirokuForms and see how fast pure HTML forms can be. Boost your user experience!