

High-Performance Language Models: Data Sovereignty and Cost Efficiency
Data Sovereignty Through Decoupled Architecture

The primary consideration for deploying language models involves balancing cost, capability, and data ownership.
Codebases, internal documents, and customer records form a competitive advantage. The problem with consumer chat applications is that they prioritise user convenience over data security. They frequently absorb user inputs into future training runs or suffer data breaches.
A secure approach requires bypassing consumer interfaces in favour of direct API access. This ensures precise control over data routing and model selection, however can be very costly.
The Economics of Compute
Model pricing reflects underlying compute requirements. Users pay for compute per token, and there is a wide range of prices. These differences form distinct tiers.
Commodity models minimise cost per token and maximise throughput. They are used for bulk processing where precision is less critical.
Efficient high-quality models use techniques such as sparse activation to approach frontier-level quality at much lower cost. They define the current price-performance frontier and handle most real workloads.
General-Purpose models trade some efficiency for consistency and broader capability. They are often used as defaults when reliability matters but cost still matters.
Frontier models maximise reasoning depth and success rate. They use more compute per token and are priced based on task value rather than raw cost.
Across all tiers, providers may price models at or below cost to gain market share and establish default backends. This is most visible in efficient models, where low compute requirements make aggressive pricing sustainable, but the same strategy can apply more broadly where ecosystem control is the goal.
Efficient architectures reduce cost through quantisation, optimised inference, and amortised hardware. Kimi is a clear example, offering large context windows for bulk processing at low cost.
Frontier models take a different approach. They use more compute per token and often perform additional internal reasoning steps. This increases cost and latency but improves reliability. Their pricing reflects the value of solving a task rather than the raw compute required.
Efficient models optimise for cost and scale, while frontier models optimise for correctness and success rate. A cheaper model may require multiple iterations, increasing total token usage. A more expensive model may solve the same problem in one pass with fewer tokens and less coordination.
OpenRouter, Kimi, and TypingMind
A practical implementation in a company separates the interface from the underlying model. Many users default to expensive subscriptions like Claude Max Ultimate. Organisations can achieve superior results through decoupling. OpenRouter provides an API layer to route requests to the most efficient model. Users can direct bulk tasks, refactoring, and document analysis to Kimi. They reserve the frontier models strictly for final debugging or architectural decisions.
For daily interaction outside the terminal, TypingMind serves as a secure interface. It stores chat history locally and connects directly to OpenRouter API keys. This setup replicates the premium chat experience without exposing proprietary data to consumer training loops or requiring fixed monthly costs. Utilising direct APIs ensures data remains outside of vendor training pipelines. This satisfies baseline compliance requirements.
Conclusion
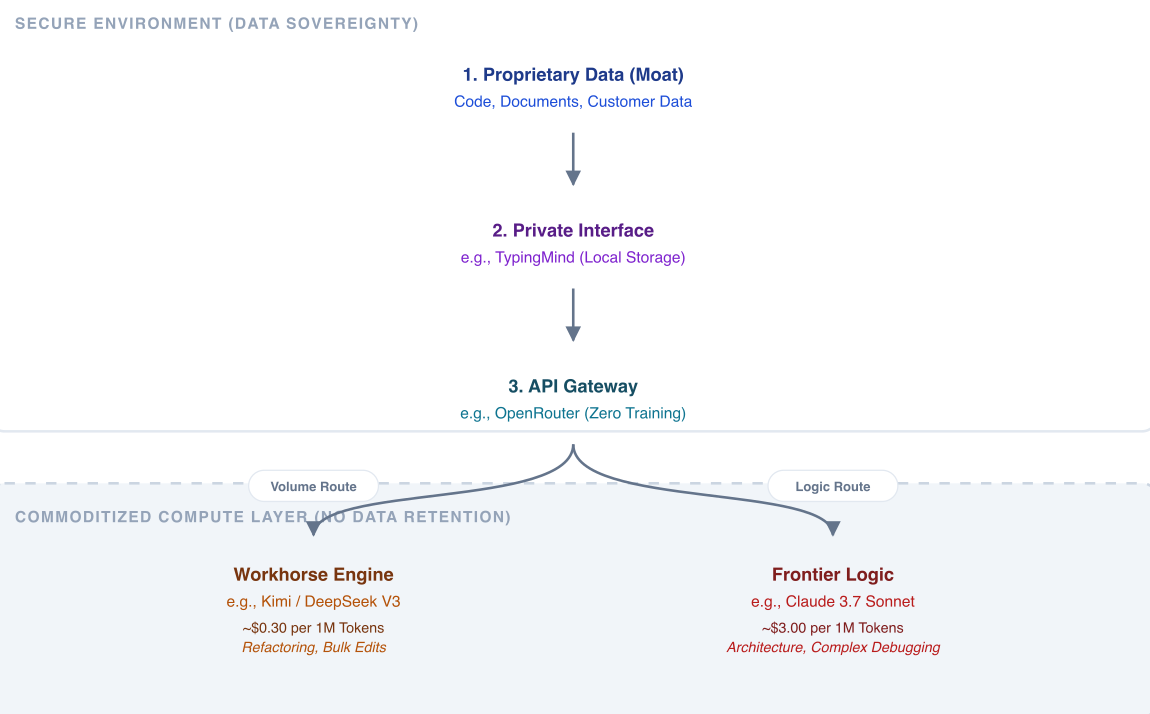
The market provides tools to maintain data sovereignty while reducing operational costs. By utilising decoupled interfaces like TypingMind, routing requests through OpenRouter, and leveraging quantised models like Kimi for volume tasks, users optimise their workflows. This structure secures proprietary data and aligns expenses directly with computational requirements.
Chelsea AI Ventures provides advice on AI implementation and helps with development and integration of AI and ML technologies into products.